首先更新一下第一次实验关于堆栈的分析,这里我直接手写拍的图片。
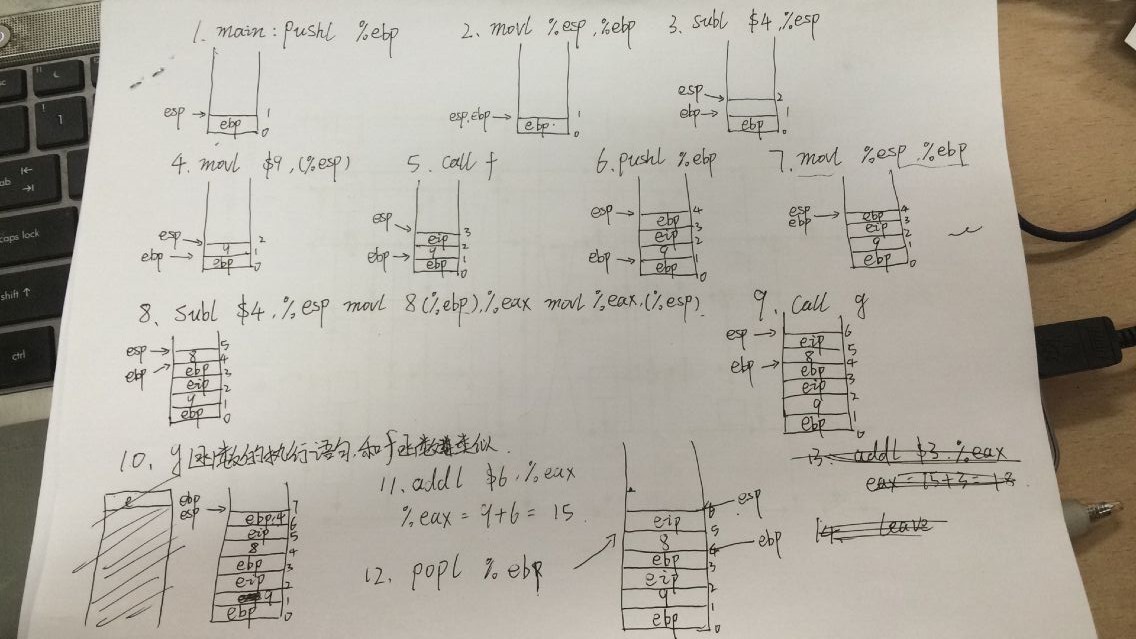

这里再补充一点,第5步的call f 实际上等于 pushl %eip,movl f %eip,也就是将f的eip地址压栈,call g原理相同。leave等于movl %ebp,%esp,popl %ebp 也就是将ebp出栈,epb指向自己所存储值的栈,再将ebp的值付给esp,实现栈的释放。
接下来是实验:
2014年9月24日,Bash中发现了一个严重漏洞shellshock,该漏洞可用于许多系统,并且既可以远程也可以在本地触发。
什么是shellshock:Shellshock,又称Bashdoor,是在Unix中广泛使用的Bash shell中的一个安全漏洞,首次于2014年9月24日公开。许多互联网守护进程,如网页服务器,使用bash来处理某些命令,从而允许攻击者在易受攻击的Bash版本上执行任意代码。这可使攻击者在未授权的情况下访问计算机系统。
实验准备:
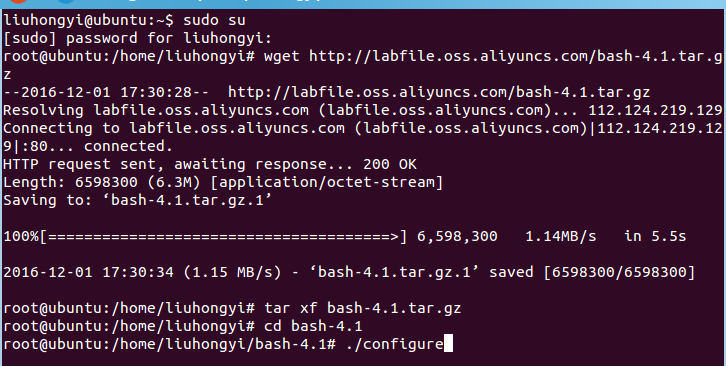
以root权限安装4.1版bash
下载:
# wget http://labfile.oss.aliyuncs.com/bash-4.1.tar.gz
安装:
# tar xf bash-4.1.tar.gz# cd bash-4.1# ./configure# make & make install
链接:
# rm /bin/bash# ln -s /usr/local/bin/bash /bin/bash
检测是否存在shellshock漏洞:
$ env x='() { :;}; echo vulnerable' bash -c "echo this is a test " 以下是实验截图:
出现问题以及解决方案:
第一次实验的时候粗心大意没有sudo出现了权限不够的问题
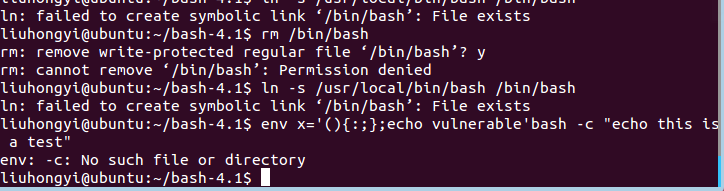
解决以后又出现新的问题,当执行bash -version 时,出现如下的提示信息:

根据提示执行sudo apt-get install bash 后出现如下错误:
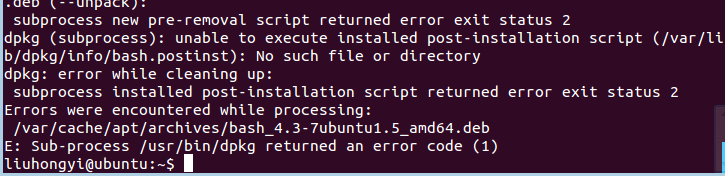
上网百度了一下,是dpkg的错误,尝试了网上的几种方法,未能成功解决。接着返回实验楼的实验环境进行实验。
攻击Set-UID程序:
$ sudo ln -sf /bin/bash /bin/sh
编译下面这段代码,并设置其为Set-UID程序,保证它的所有者是root。我们知道system()函数将调用"/bin/sh -c" 来运行指定的命令, 这也意味着/bin/bash 会被调用
#includevoid main(){ setuid(geteuid()); // make real uid = effective uid. system("/bin/ls -l");}
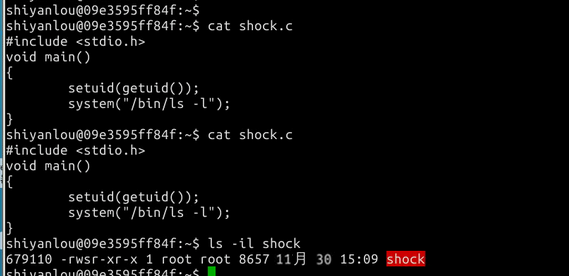
如果 setuid(geteuid()) 语句被去掉了,再试试看攻击,并无法成功。
void initialize_shell_variables(){// 循环遍历所有环境变量for (string_index = 0; string = env[string_index++]; ) { /*...*/ /* 如果有export过的函数, 在这里定义 */ /* 无法导入在特权模式下(root下)定义的函数 */ if (privmode == 0 && read_but_dont_execute == 0 && STREQN (“() {“, string, 4)) { [...] // 这里是shellshock发生的地方 // 传递函数定义 + 运行额外的指令 parse_and_execute (temp_string, name, SEVAL_NONINT|SEVAL_NOHIST);[...]} } 就是上述那一行判断逻辑导致了两者的不同,primode即私有模式,要求real uid 与 effective uid保持一致。
实验到此基本结束。
书上内容总结:
Linux设备包括三种,块设备,字符设备,网络设备,第十七章主要讨论内核功能黑鸡设备驱动的实现和设备树的管理,包括模块,kobject和sysfs。
linux的可移植性:
1.字节和数据类型
能够由机器一次就完成处理的数据被称为字,字指位的数目。所以我们常听到机器是多少位的时候,就是指该机的字长。处理器通用寄存器的大小和它的字长是相同的。C语言定义的long类型总对等于机器字长。对于支持的每一种体系结构,Linux都要将<asm/types.h>中的BITS_PER_LONG定义为C long类型的长度,也就是系统的字长。不透明类型是那些通过typeder声明的类型。另外就是,我们常常需要在程序中使用长度明确的类型,内核在asm/types.h中定义了这些长度明确的类型,而该文件又被包含在文件linux/types.h中,如下表所示:

其中带符号的变量用的比较少。接下来是char型:分为有符号(-128~127)和无符号(0~255).
2.数据对齐
如果一个变量的内存地址正好是它长度的整数倍,它就被称为自然对齐的。关于字节对齐的内容还是相当繁琐的,我这里就不细讲了,后面我会有专门的专题来说这个问题。
3.字节顺序
字节顺序是指在一个字中各个字节的顺序。处理器在对字取值时既可能将最低有效位所在字节当作第一个字节(最左边的字节),也可能将其当作最后一个字节(最右边的字节)。如果最高有效位所在的字节放在最高字节位置上,其他字节依次放在低字节位置上,那么该字节顺序称作高位优先(big-endian)[存放左大右小],否则就叫做little-endian[左小又大].直接举个例子,如下:
00000000 00000000 00000100 00000011

下面是上述数据在两种不同字节序的排列方式:

虽然不习惯,但确实是这样的,使用高位优先的体系结构把最高字节位存放在最小的内存地址上。下边的代码可以判定给定的机器字节对齐类型:
int x = 1;if (*(char *)&x == 1) /* little endian */else /* big endian */
在Linux内核支持的每一种体系结构,相应的内核都会根据机器使用的字节顺序在它的asm/byteorder.h中定义__BIG_ENDIAN或__LITTILE_ENDIAN中的一个。,这个头文件还从include/linux/byteord er中包含了一组宏命令完成字节顺序之间的相互转换,最常用的宏命令如下:
u23 __cpu_to_be32(u32); /* convert cpu's byte order to big-endian */u32 __cpu_to_le32(u32); /* convert cpu's byte order to little-endian */u32 __be32_to_cpu(u32); /* convert big-endian to cpu's byte order */u32 __le32_to_cpus(u32); /* convert little-endian to cpu's byte order */
4.时间
关于内核的时间问题,绝对不要假定时钟中断发生的频率,也就是每秒产生的jiffies数目。相反,应该使用HZ来正确计量时间。
5.页长度
当处理用页管理的内存时,绝对不要假设页的长度。不同的体系结构使用页的长度也是不一样的。当处理用页组织管理的内存时,通过PAGE_SIZE来使用以字节数来表示的页长度,而PAGE_SHIFT这个值定义了从最右端屏蔽多少位能够得到该地址对应的页的页号。
总之,编写可移植的代码需要考虑许多问题:字长,数据类型,对齐,字节次序,页大小,处理器排序等等。